
Here we can see, “How to Use Tesseract for OCR from the Linux Command Line”
The Tesseract OCR engine can extract text from photos via the Linux command line. It’s quick, accurate, and supports over 100 languages. Here’s how to put it to good use.
OCR stands for Optical Character Recognition.
The capacity to look at and detect words in an image and then extract them as editable text is known as optical character recognition (OCR). This simple task is extremely tough for computers to do. The early attempts were clumsy. If the typeface or size was not to the OCR software’s liking, computers were frequently puzzled.
Nonetheless, the forerunners in this sector were held in high regard. If you lose the electronic copy but still have the printed original, OCR can re-create an electronic, editable version of a document. Even if the outcomes weren’t perfect, it was still a significant time-saver.
You could get your document back with some manual cleanup. People forgave the errors it made because they recognized the difficulty of the task an OCR program faced. It was also preferable to retyping the entire document.
Since then, things have vastly improved. Hewlett Packard’s Tesseract OCR application was first released as a commercial product in the 1980s. It was released as open-source software in 2005 and is now sponsored by Google. It supports multiple languages, is widely considered one of the most accurate OCR systems available, and is entirely free to use.
Tesseract OCR Installation
Use the following command to install Tesseract OCR on Ubuntu:
sudo apt-get install tesseract-ocr
The command in Fedora is:
sudo dnf install tesseract
You must type the following on Manjaro:
sudo pacman -Syu tesseract
Tesseract OCR (Optical Character Recognition)
Tesseract OCR will be faced with a series of obstacles. An excerpt from Recital 63 of the General Data Protection Regulations is our first image with text. Let’s see if OCR can make sense of this (and stay awake).

Because each phrase begins with a faint superscript number, which is common in legislative documents, it’s a challenging image.
We must provide the following information to the tesseract command:
- The name of the image file that we’d like it to work with.
- The name of the text file in which the extracted text will be saved. We don’t have to give the file extension if we don’t want to (it will always be .txt). If a file with an identical name already exists, it will be overwritten.
- The —dpi option can be used to tell Tesseract what the image’s dots per inch (dpi) resolution is. Tesseract will try to figure out the dpi value if we don’t offer one.
Our picture file is called “recital-63.png,” and it has a 150-dpi resolution. We’re going to save it as “recital.txt” in a text file.
This is what our command looks like:
tesseract recital-63.png recital --dpi 150
The outcomes are excellent. The only problem is that the superscripts are too faint to read correctly. To get good results, you’ll need a high-quality photograph.

Tesseract has read the superscript numerals as quote marks (“) and degree symbols (°), but the actual content has been perfectly retrieved (the right side of the image had to be trimmed to fit here).
The final character is a carriage return, represented by a byte with the hexadecimal value of 0x0C.
Another graphic with text in various sizes and bold and italics are shown below.

“bold-italic.png” is the name of the file. We wish to make a text file called “bold.txt,” thus we’ll use the following command:
tesseract bold-italic.png bold --dpi 150
This one went without a hitch, and the text was perfectly extracted.

Using a Variety of Languages
Tesseract OCR supports around 100 languages. You must first install a language before you can use it. Make a note of the abbreviation for the language you want to use in the list. We’re going to enable Welsh support. The abbreviation “cym” stands for “Cymru,” which means “Welsh.”
“tesseract-ocr-” is the installation package’s name, with the language abbreviation appended at the end. We’ll use the following commands to install the Welsh language file on Ubuntu:
sudo apt-get install tesseract-ocr-cym
Below is an image with the words. It’s the Welsh national anthem’s opening verse.

Let’s check if Tesseract OCR can handle the task. To tell Tesseract whatever language we want to work in, we’ll use the -l (language) option:
tesseract hen-wlad-fy-nhadau.png anthem -l cym --dpi 150
As evidenced in the excerpted text below, Tesseract performs admirably. Tesseract OCR, da iawn.

You can use a plus sign (+) to inform Tesseract to add another language if your document contains two or more languages (for example, a Welsh-to-English dictionary).
tesseract image.png textfile -l eng+cym+fra
Working with PDFs with Tesseract OCR
The tesseract command was created to operate with picture files, but it cannot read PDF files. If you need to extract text from a PDF, you can generate photos with another program first. A single image will be used to represent a single PDF page.
Your Linux PC should already have the pdf program installed. We’ll use a PDF of Alan Turing’s fundamental article on artificial intelligence, “Computing Machinery and Intelligence,” as our example.

To signal that we wish to create PNG files, we use the -png option. “turing.pdf” is the name of our PDF file. Our picture files will be named “turing-01.png,” “turing-02.png,” and so on:
pdftoppm -png turing.pdf turing
We need to utilize a for loop to run Tesseract on each image file with a single command. We use Tesseract to create a text file named “text-” plus “turing-nn” as part of the image file name for each of our “turing-nn.png” files:
for i in turing-??.png; do tesseract "$i" "text-$i" -l eng; done;
To combine all the text files into one, we can use cat:
cat text-turing* > complete.txt
So, how’d it turned out? As you can see below, everything went swimmingly. However, the first page appears to be extremely difficult. It has a variety of text styles and sizes, as well as adornment. On the right border of the page, there’s also a vertical “watermark.”
The output, on the other hand, is very close to the original. The formatting has been gone, but the text is correct.
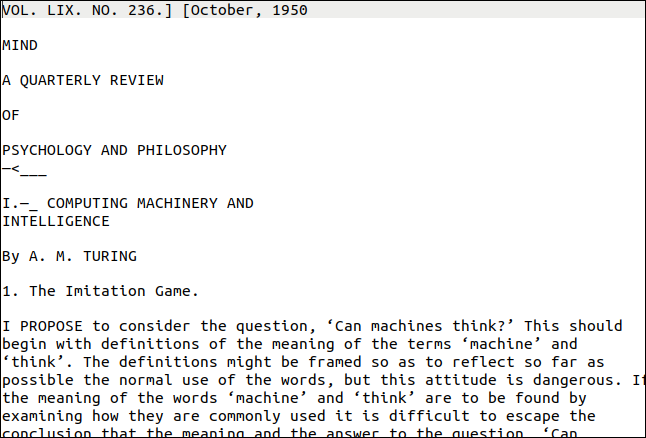
At the bottom of the page, the vertical watermark was transcribed as a line of gibberish. The text was too small for Tesseract to read accurately, but it would be simple to locate and remove. Having stray characters at the end of each line would have been the worst-case scenario.
Surprisingly, the single letters at the beginning of the second page’s list of questions and answers have been omitted. The following is a passage from the PDF.

The questions are still there, but the “Q” and “A” at the beginning of each line have vanished.

Diagrams will also be incorrectly transcribed. Examine what occurs when we attempt to extract the one displayed below from the Turing PDF.

The characters were real, but the diagram format was lost, as you can see in our result below.

The modest size of the subscripts caused Tesseract to struggle once more, and they were drawn erroneously.

But, to be fair, that was still a good result. We could not extract simple text, but this case was picked specifically because it was a problem.
Conclusion
I hope you found this information helpful. Please fill out the form below if you have any queries or comments.
User Questions:
- What is Tesseract Linux, and how can I use it?
- On an Ubuntu installation, Tesseract is used. Installing Dependencies (1.1)
- It’s being run. Select a picture containing text and run the following command in the console (assuming the input filename is img.png): out Tesseract img.png
- Using Tesseract with Python. Python-tesseract is a Python wrapper for Tesseract-OCR from Google.
- Is this an OCR input or an OCR output?
OCR stands for optical character recognition, and it is a device that reads printed text. Character by character, OCR scans the text optically, turns it into a machine-readable code, and saves it in the system memory.
- How does the Tesseract algorithm work?
This technique is capable of decrypting and extracting text from a wide range of sources! It makes use of an improved version of the tesseract open source OCR technology, as its name suggests. We also use binarization to automatically binarize and preprocess photos so that Tesseract has an easier time decrypting them.
- Can someone please tell me how to use tesseract OCR
Can someone please tell me how to use tesseract OCR from linux4noobs
- tesseract png > pdf stopped working
Images credits: howtogeek



{kind=link}